
How to Be Awesome at Biostatistics and Literature Evaluation - Part II

Well that escalated quickly. We covered quite a bit in Part I of this post. I started with why you should care about and learn biostats. Then we jumped into a bunch of terms and concepts that you need to shore up your biostats and literature evaluation skills.
Now, I'm going to pivot slightly. This post will cover more "essential" concepts. But the stuff covered in Part I was foundation concepts such as types of data, and measures of central tendency (mean, median, and mode). This post will explore the more applied concepts such as odds, risk, hazards, and correlation. These concepts are the heart of inferential statistics because they represent different ways of comparing one thing to another (which we can use to make predictions). I'll talk about the strengths and weaknesses of each of them.
The purpose of all of this is to get the fundamentals in order, so you can go out and actually apply all of the lessons contained in this series. Part III will dig a little deeper into the types of statistical tests and when to use them. It'll also cover all of the various types of trials and studies that you'll come across in medical literature. Finally, Part IV will be all about literature evaluation, and how to do it effectively. But for now, let's finish laying the foundation of inferential statistics.
As an FYI, you can also get this entire series (Parts I - IV) consolidated into a single printer-friendly and savable PDF. You can find that here.

Risk versus Odds
In everyday language, it's common to use risk and odds interchangeably. In statistics, however, that's a big no-no. Risk and odds are not the same thing; and it's important to differentiate between them.
Risk = [The chance of an outcome of interest] / [All possible outcomes]
Odds = [Probability of event to occur] / [Probability of event not occurring]
So risk and odds are close; but they calculate different things and cannot be used interchangeably. Let's illustrate with an example. Let's look at a hypothetical group of 100 smokers. Let's say that 35 of these 100 smokers develop lung cancer, and that 65 do not.
The risk of lung cancer is 35 / 100 = 0.35 = 35%
The odds of lung cancer are 35 / 65 = 0.54 = 54%
Slightly different, right?
However, there is a case when the values of risk and odds are very close. When the event rate is very low (usually less than 10%), risk and odds are very close in value. But even for these rare events, the terms shouldn't be used interchangeably; they just happen to have similar values.
When should you use risk; and when should you use odds?

This article does a great job of answering this question. It's a quick read, and definitely worth your time. I'll summarize the key points here. Think about the parameters that go into calculating risk and odds. Risk requires the use of "people at risk" in the denominator. In a retrospective study, we can't use risk because we don't know the total number of exposed people. If the study is retrospective, you need to use odds, where you can measure the strength of the association between exposure and outcome. However, in a prospective study, you can use risk (because the total number of people exposed is available). You can actually use odds in a prospective study too, because you have the information needed to calculate it. So to summarize:
Retrospective study (i.e. case-control) - use odds
Prospective study (i.e. cohort) - use risk or odds
Relative Risk (RR)
Also known as the risk ratio. It is the probability of an event occurring in the treatment (exposed) group versus the placebo (non-exposed) group. This is usually expressed as a ratio and then converted to a percent. For example...
In the study I'm making up as I'm typing, let's say that we compared Drug A to placebo in the treatment of hypertension. 9% of patients taking Drug A developed hypertensive urgency compared to 28% of the patients in the placebo group. Our relative risk here would be:
Treatment Event Rate / Control Event Rate = RR
Or you could type it as:
Incidence of exposed subjects / Incidence of unexposed subjects = RR
Either way, for this example, we get:
9 / 28 = 0.32
We would interpret this by saying "Patients taking Drug A are only 32% as likely to develop hypertensive urgency compared to placebo." Note that you have to say AS likely here (even though it probably makes you uncomfortable to do so).
You won't say LESS likely until you're dealing with relative risk reduction (which I'll get to in a minute...but if the suspense is killing you, the relative risk reduction in this example is 1 - 0.32 = 0.68 = 68%).
You don't need a placebo group to calculate RR. You could compare Drug A to anything, including standard of care. Because of the term "risk," we typically use RR to interpret the likelihood of unfavorable events. In the example above, we compared the rate of hypertensive urgency (an unfavorable event) in two groups. You could also compare the incidence of an unwanted side effect (like nausea, vomiting, rash, etc...) in the treatment group versus the control group. The job of RR is to compare the likelihood of an unfavorable event occurring in one group versus another.
You can also determine statistical significance with RR. Because it's a ratio, a relative risk of 1 means there is no difference between treatment groups (because 1 / 1 = 1). So if the Confidence Interval (CI) for relative risk contains the number 1, then that result is insignificant. You don't need a p-value here. I wrote more about this in Part I of this series, so go back and check that out if you need a refresher.
To further use RR for data interpretation, a RR of < 1 means that the intervention reduced the rate of the unfavorable outcome. In our example above, the treatment group was 32% as likely to develop hypertensive urgency.
On the other hand, a RR of > 1 means that the risk was increased in the intervention group. So to summarize:
RR < 1: Reduced rate of unfavorable outcome
RR = 1: No difference in rate of unfavorable outcome (also statistically insignificant)
RR > 1: Increased rate of unfavorable outcome
I'll talk more about it below with relative risk reduction, but the general "weakness" of relative risk is that it tends to over-inflate the treatment benefit of a given group.
Odds Ratio (OR)
OR and RR are similar enough to be easily confused, but as mentioned above in the "Risk versus Odds" section, they are very different. Just as relative risk is a comparison of risk in two different groups, odds ratio is a comparison of odds in two different groups. OR is just the ratio of two different sets of odds.
As mentioned above, we primarily use OR for retrospective studies such as case controls. Similar to RR, we can use the confidence interval of OR to determine statistic significance. That looks basically the same as RR:
OR < 1: Exposure associated with lower odds of outcome
OR = 1: Exposure does not affect odds of outcome (also statistically insignificant)
OR > 1: Exposure associated with higher odds of outcome
So just like with RR, if the confidence interval of OR crosses 1, then the data result is insignificant. Here's a solid reading on OR if you'd like more information.
And for a final comparison of RR to OR, it's useful to chart the exposure history with cases and controls. You've seen this box before:

And if you haven't seen it, you eventually will on a test in the future. These "Punnett Square" looking things are a useful way to visually see the difference between OR and RR. It makes calculating OR and RR much easier because you can just plug in the numbers from the study. Chart exposure risk (positive or negative) on the rows on the left side. Then on the columns up top, you put disease status (yes or no). Then, use the respective formulas for OR and RR.
Just don't get caught on a test by calculating the wrong one. Remember, that we cannot use RR for a retrospective study (like a case control). So if that's what you're working with, use OR. If it's a prospective study, you can calculate both OR and RR with the same data.
Relative Risk Reduction (RRR)
How much the risk is reduced in the experimental group compared to the control group. Numerically, it's easy to calculate. Just take the relative risk (which we calculated above) and subtract it from one (note that you must use the decimal form of relative risk).
RRR = 1 - RR
Technically, you can also calculate RRR by dividing ARR by the control event rate (CER). You will pretty much never have to do this in real life, but you may be asked to on a test. So again, here's another way of getting to RRR:
RRR = ARR / CER
You will run into RRR a lot when reading medical literature. It's easier to understand conceptually than relative risk because it's easier for our brains to grasp "this thing lowers my chance of heart attack compared to this other thing." With RR you're just getting a ratio, whereas with RRR you're getting a percentage increase or decrease.
The "weakness" of RRR is that it doesn't tell you anything about the generalizability of the study (i.e. how much the results apply to the population at large). Effectively, this means that RRR tends to over inflate the treatment effects of a given intervention. The cynic in me thinks this is why the RRR is what tends to be reported in medical literature. It's often a sexier number.
In order to measure the effect on the population at large, you need a different number altogether (Absolute Risk Reduction). By its very nature, RRR only applies to the study population of the paper you're reading (although the headlines and advertisements won't tell you that).
Absolute Risk Reduction (ARR)
I'm so passionate about ARR that I wrote an entire post about it here. Check that for more information, and I'll just give a quick summary here.
If RRR measures our risk of something compared to something else, ARR measures our risk of something compared to something else while accounting for the actual likelihood the event will happen in the population at large.
For example, let's we're looking at a trial that measures the impact of a new drug (Drug X) compared to placebo on the incidence of stroke. And throughout the trial, the incidence of stroke in the Drug X group was 2%; while the incidence of stroke in the placebo group was 4%. Mathematically, the ARR is simply the Control Event Rate (CER) minus the Experimental Event Rate (EER):
ARR = CER - EER
So using our numbers above, we have 4% - 2%, which we convert to decimal points to get 0.04 - 0.02 = 0.02.
The ARR of Drug X in this case is 2%. Nothing to sneeze at when it comes to stroke. But for comparison's sake, remember from above that we can also use ARR to figure out the RRR:
RRR = ARR / CER
In this case, you'd get 0.02 / 0.04...corresponding to a RRR of 50%.

Remember: The ARR Pirate is watching...
The marketing team for Pfizer would quiver with delight with a number like that. And the RRR will be what's reported to you, because 50% makes for better press than 2%.
So again, I cannot stress enough: Please calculate ARR. You'll have to take it upon yourself, but do it for every study you read. It's the only way to get a true handle on the actual effect size of any given intervention.
Number Needed to Treat (NNT)
Mathematically, the NNT is just the inverse of Absolute Risk Reduction (ARR).
NNT = [1 / ARR]
Conceptually, it's the number of patients you need to treat to prevent one event. In the ARR post above, I used the example of the heart failure drug, Entresto. Entresto reduces your absolute risk of dying from cardiovascular death by 3.2% (0.032). So our NNT would be:
1 / 0.032 = 32

Not you.
In other words, you need to treat 32 patients with Entresto in order to prevent one cardiovascular death. ARR and NNT are things that you should calculate with every single study you read (you'll have to calculate them because they're almost never reported). They lend context and perspective to study results, and help prevent you from getting tied up in the 'sexy' RRR number that makes the news headlines.
Number Needed to Harm (NNH)
The evil cousin of NNT is NNH. It's the number of patients you need to treat to cause some bad outcome. It's a measure of adverse effects as opposed to treatment benefits. It's calculated in the same way as NNT, but instead of using ARR, we use something called the Attributable Risk (AR).
NNH = [1 / AR]
Attributable risk is also very similar to absolute risk reduction. Remember from above that ARR is calculated by taking the control event rate - the experimental event rate
ARR = CER - EER
Attributable risk is identical, except that instead of dealing with event rates, you're dealing with exposure. So it's calculated by subtracting the incidence of individuals exposed to the risk factor minus the incidence of individuals not exposed. I'll call them Exposed Event Rate (EER) and Non-Exposed Event Rate (NER)
AR = EER - NER
Note that I just made up the acronyms EER and NER, so if you're fact checking me I doubt you'll find them used anywhere else. The "risk factor" or "exposure" in this case is the drug treatment. Let's use an example of bradycardia caused by metoprolol. To calculate AR, we'd do the following:
AR = Bradycardia in patients taking metoprolol - Bradycardia in patients not taking metoprolol
And then NNH is just 1 / AR.
Hazard Ratio
A 'hazard' here is a negative outcome. "Death" is often the negative outcome hazard ratio is referring to; but it could also be some other undesirable event like an adverse effect or disease progression. You'll see hazard ratio analyses show up frequently in oncology literature. The word "ratio" implies that we're measuring the rate of this negative event in one group (patients receiving Treatment X) compared to another group (patients receiving Treatment Y).
Hazard Ratio is similar to the OR and RR above in that a hazard ratio of 1 means there is no difference between the event rate in the two groups. A hazard ratio of less than one means there is a lower risk of the negative event occurring in that group. A hazard ratio of greater than one implies a greater risk.
Correlation
A measurement of the relationship between two variables. You'll often see this as a graph of a scatter plot with a line of "best fit" going through the various points of data. One variable is represented on the x-axis, and the other is represented on the y-axis.
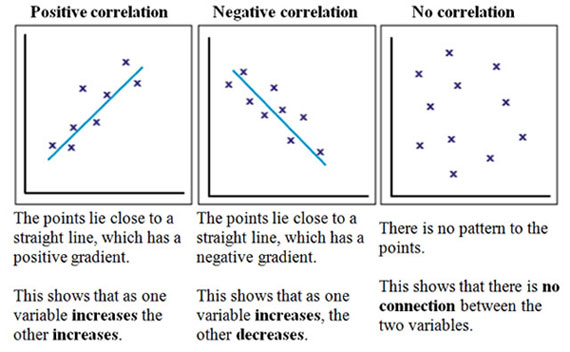
That line is usually distilled down to a signal number, called the correlation coefficient. There are actually several correlation coefficients used in statistics land, but in clinical literature you'll pretty much only see the Pearson Correlation Coefficient (abbreviated r). The Pearson Correlation Coefficient ranges between -1 and 1; meaning that you can measure both direction and magnitude with it.
If r is 0, then there is no correlation between the two variables (the picture on the right above). If r is positive, then the two variables will increase or decrease together (you would call them "positively correlated"). And if r is negative, the two variables are inversely related (when one increased, the other decreases). You'd call these (wait for it)...negatively correlated. The closer r is to -1 or 1, the stronger the correlation. And the closer r is to 0, the weaker the correlation.
Incidence
The proportion of new cases of a disease occurring during a specified period of time. The big difference between incidence and prevalence (which we'll get to next) is that incidence is focused on new cases.
Prevalence
The proportion of existing cases of a disease during a specified period of time. So your key word here is existing cases.

With your incidence and prevalence powers combined, I can tell you if diabetes is getting worse in the US. (Image)
Incidence and prevalence are often confused on pharmacy school tests, so let's try to hammer the difference home. Notice that both incidence and prevalence are tied to a specified period of time. They have to be, if you think about it. If you're measuring the number of new cases of diabetes in the US, you have to answer the question "New since when?" The incidence of diabetes in the time period of 2015 would be very different than the incidence in the period of 2011 - 2015. We can use incidence and prevalence together to determine how the rate of a given disease is changing in a population.
To steal a single sentence summary from wikipedia: "Incidence conveys information about the risk of contracting the disease, whereas prevalence indicates how widespread the disease is."
Diagnostic Tests
In medicine, we've developed diagnostic tests to help determine the presence of a disease when certain symptoms or risk factors are present. Examples include Fecal Occult Blood Test (FOBT), the rapid Strep test, and the OraQuick HIV test.
However, no diagnostic test is 100% accurate. And we have to account for that when using them. We've actually developed a few ways of measuring how accurate a diagnostic test is. Specifically, we measure the Sensitivity, the Specificity, the Positive Predictive Value (PPV), and the Negative Predictive Value (NPV).
Sensitivity - The ability of a diagnostic test to correctly identify individuals with the disease (aka: the ability to identify true positives)
Specificity - The ability of a diagnostic test to correctly identify individuals without the disease (aka: the ability to identify true negatives)
Positive Predictive Value (PPV) - The probability that individuals who test positive for the disease actually have the disease
Negative Predictive Value (NPV) - The probability that individuals who test negative for the disease actually DO NOT have the disease
You may have some difficulty untangling Sensitivity and PPV (and/or Specificity and NPV). I know I sure do. The way that I get through it is to think about the focus of each. The focus of sensitivity and specificity is on the test. Whereas the focus on PPV and NPV is on the patient. You could try re-stating them as follows:
Sensitivity is the probability that the test is positive when the disease is present. Whereas PPV is the probability that the disease is present when the test is positive.
And likewise, specificity is the probability that the test is negative when the disease is not present. And NPV is the probability that the disease is not present when the test is negative.
After racking my brain around this all for many hours, the only conclusion I can come to is that statisticians are just inherently evil people. I kid, I kid :)
All of these concepts can easily be illustrated with pretty much the exact same grid that we used for OR and RR:

Doesn't this look familiar? Image
We just tweak it slightly to use it with diagnostic tests. In the rows, you put whether the test read positive or negative. Then in the columns you put the actual presence of the disease (or not). Then, you've got the formulas right there to calculate Sensitivity, Specificity, PPV, and NPV. Pretty handy, right?
Get This Series as a PDF!
Want to save this article to view offline? Or have a more printer-friendly version? You can get the entire series of How to Be Awesome at Biostatistics and Literature Evaluation as a single printer-friendly and convenient PDF.